Build journal rule¶
Previous requirements¶
- Knowledge about regular expressions
- Knowledge of the structure of rules definition file
- Any text editor of your preference. (SublimeText, Notepad++, etc...)
- Recommend use RegexBuddy you need pay, but can generate quickly and easy, patterns of regex.
- Reference sample of the journal which will create the rule.
Build main pattern¶
NOTE: To write this manual used a journal Revista mexicana de biodiversidad ISSN: 1870-3453
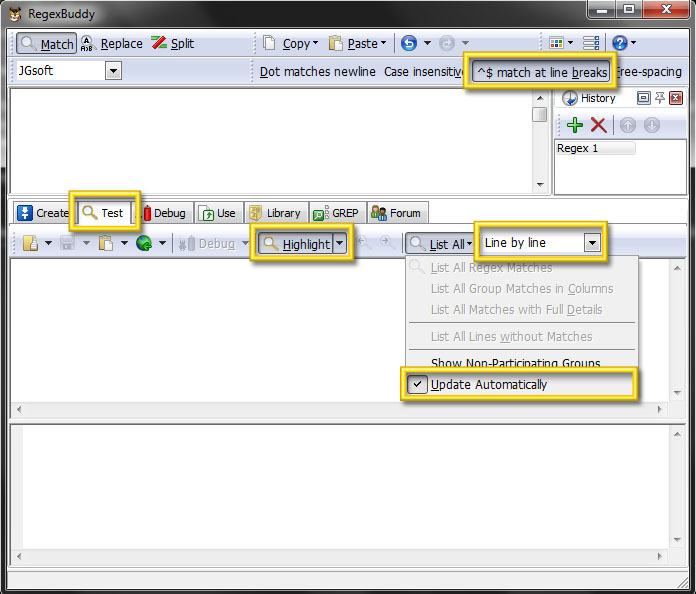
- Open RegexBuddy and check ^$ match at line breaks, chosse tab Test, check Highlight, in List All submenu check Update Automatically and choose Line by line like this:
- Paste sample of references in Test tab. The larger the sample will be obtain better results.
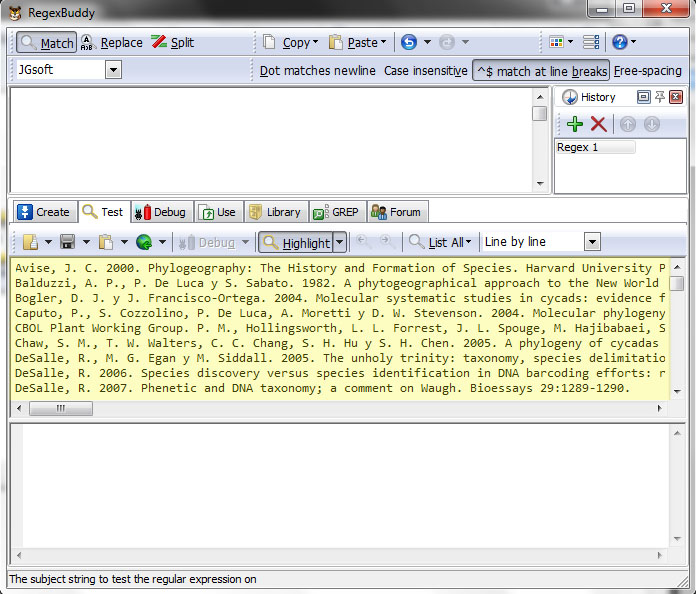
- Now it’s time to use and increment your knowledge of regex. First you need identify patterns in references, like a field separators (., ;, :, etc). In this case can identify from left to right, 1 authors, 2 space, 3 date.
authors
space
date
Avise, J. C.
|_|
2000
Balduzzi, A. P., P. De Luca y S. Sabato.
|_|
1982
Bogler, D. J. y J. Francisco-Ortega.
|_|
2004
Caputo, P., S. Cozzolino, P. De Luca, A. Moretti y D. W. Stevenson.
|_|
2004
Chaw, S. M., T. W. Walters, C. C. Chang, S. H. Hu y S. H. Chen.
|_|
2005
DeSalle, R., M. G. Egan y M. Siddall.
|_|
2005
DeSalle, R.
|_|
2006
DeSalle, R.
|_|
2007
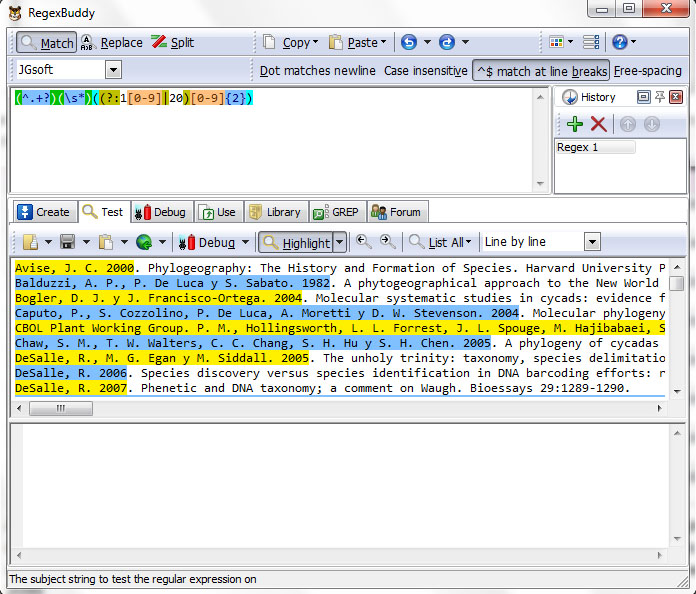
And you can represent this by regex (^.+?)(\s*)((?:1[0-9]|20)[0-9]{2}), groups is:
(^.+?) .- ^ Begin of line match . any single caracter + betwen one and ulimited times ?, as few times is posible. This group identifies authors.
(\s) .- Match a \s sigle white space character (space, tabs, and line breaks).
((?:1[0-9]|20)[0-9]{2}) .- Match the character 1 and numbers between [0-9] or 20, match two characters between [0-9]. This group identifies dates between 1000 and 2099.
Now put the regex (^.+?)(\s*)((?:1[0-9]|20)[0-9]{2}) in RegexBuddy and see the automatic highlight maresults.
The next pattern is, dot and space, title, dot and space, publisher name, space, pages, and end with dot. And can represented by next regex (\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$) with groups:
(\.\s) .- Match \. dot and \s space.
(.+?) .- Match . any single caracter + betwen one and ulimited times ?, as few times is posible.
(\.\s) .- Match \. dot and \s space.
(.+?) .- Match . any single caracter + betwen one and ulimited times ?, as few times is posible.
(\s) .- Match \s space.
(\s[0-9:,-\s]+?) .- Match any character in class [0-9:,-\s], + betwen one and ulimited times ?, as few times is posible.
(\.$) .- Match \. and $ end of line.
And the complete pattern is (^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$) when put the complete pattern in RegexBuddy show matches in references. Whit this pattern matche with 900 references
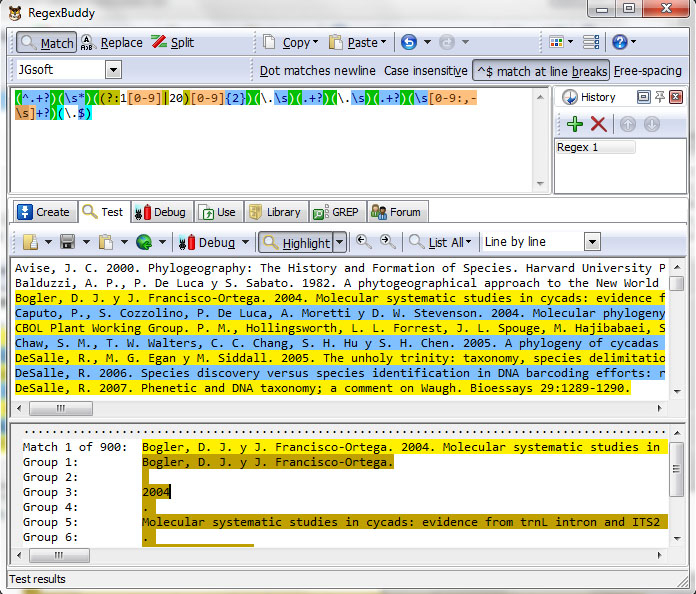
In conclusion we have the following expression (^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$) and correspond to a contribution in serial with groups:
- (^.+?) .- Authors
- (\s*) .- Space
- ((?:1[0-9]|20)[0-9]{2}) .- Date
- (\.\s) .- Dot and space
- (.+?) .- Title
- (\.\s) .- Dot and space
- (.+?) .- Publisher name
- (\s) .- Space
- ([0-9:,-\s]+?) .- Pages
- (\.$) .- Dot and end line
Add rule to xml file¶
NOTE: value, prevalue and postvalue elements contains backreference(s) group(s) in this form ${backreference} by example to backreference group 1 is ${1} and complete sintaxis is <value>${1}</value>
- First need add if not exist, main node of journal.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
<?xml version="1.0" encoding="utf-8" ?> ... <journal issn="1870-3453"> <name>Revista mexicana de biodiversidad</name> <norm>other</norm> <regex>(....+)</regex> <struct> <ocitat tag="true"> <value>${1}</value> <multiple> ... </multiple> </ocitat> </struct> <journal> ...
In all cases recommend use the main regex is (....+) and main tag of reference rule in this case ocitat, to use multiple and option‘s in each pattern to identify references.
- Add your regex pattern to a option, in multiple element node.
1 2 3 4 5 6 7 8 9 10 11 12 13
<journal issn="1870-3453"> ... <struct> <ocitat tag="true"> <value>${1}</value> <multiple> <option> <regex>(^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$)</regex> </option> </multiple> </ocitat> </struct> <journal>
Create the struct of regex pattern and add tagname elements
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
<journal issn="1870-3453"> ... <option> <regex>(^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$)</regex> <struct> <ocontrib tag="true"> <authors> <value>${1}</value> <postvalue>${2}</postvalue> </authors> </ocontrib> </struct> </option> ... <journal>
The first tagname element is ocontrib that contain authors and this tagname is only container of each author so attributte tag=”true” in tag name not used. We will see later how to parse this element.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
<journal issn="1870-3453"> ... <option> <regex>(^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$)</regex> <struct> <ocontrib tag="true"> ... <date tag="true"> <attr> <dateiso/> </attr> <value>${3}</value> <postvalue>${4}</postvalue> </date> </ocontrib> </struct> </option> ... <journal>
Second tagname on ocontrib is date with default attribute dateiso (<dateiso/> without value parse date from value if format is YYYY)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
<journal issn="1870-3453"> ... <option> <regex>(^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$)</regex> <struct> <ocontrib tag="true"> ... <title tag="true"> <attr> <language>en</language> </attr> <value>${4}</value> <postvalue>${6}</postvalue> </title> </ocontrib> </struct> </option> ... <journal>
Third tagname element is title with default attribute is language and default attribute value en
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
<journal issn="1870-3453"> ... <option> <regex>(^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$)</regex> <struct> <ocontrib tag="true"> ... </ocontrib> <oiserial tag="true"> <sertitle tag="true"> <attr> <language>en</language> </attr> <value>${7}</value> <postvalue>${8}</postvalue> </sertitle> </oiserial> </struct> </option> ... <journal>
Next tagname element is oiserial and inner tagname is sertitle with default attribute is language and default attribute value en
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
<journal issn="1870-3453"> ... <option> <regex>(^.+?)(\s*)((?:1[0-9]|20)[0-9]{2})(\.\s)(\.\s)(.+?)(\.\s)(.+?)(\s)([0-9:,-\s]+?)(\.$)</regex> <struct> <ocontrib tag="true"> ... </ocontrib> <oiserial tag="true"> ... <pages tag="true"> <value>${9}</value> <postvalue>${10}</postvalue> </pages> </oiserial> </struct> </option> ... <journal>
And last tagname element is pages
Create pattern to parse inner values¶
The advantage of RegexMarkup is can processing inner elements regardless level of these. In this example can parse each author in authors. All authors appear in previous group 1:
| authors |
|---|
| Avise, J. C. |
| Balduzzi, A. P., P. De Luca y S. Sabato. |
| Bogler, D. J. y J. Francisco-Ortega. |
| Caputo, P., S. Cozzolino, P. De Luca, A. Moretti y D. W. Stevenson. |
| Chaw, S. M., T. W. Walters, C. C. Chang, S. H. Hu y S. H. Chen. |
| DeSalle, R., M. G. Egan y M. Siddall. |
| DeSalle, R. |
| DeSalle, R. |
1 2 3 4 | <authors>
<value>${1}</value>
<postvalue>${2}</postvalue>
</authors>
|
Now need create a new regex pattern to parse each author in group 1, the easy way is:
Choose List All → List all matches of group 1 on Test tab.
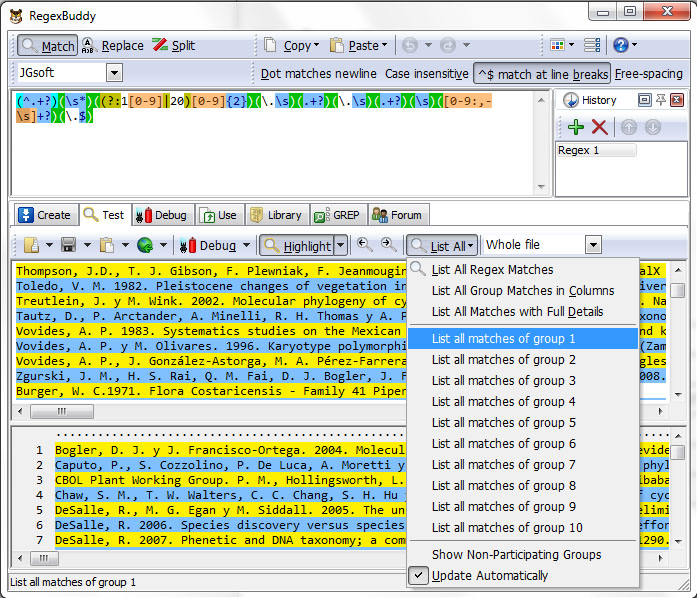
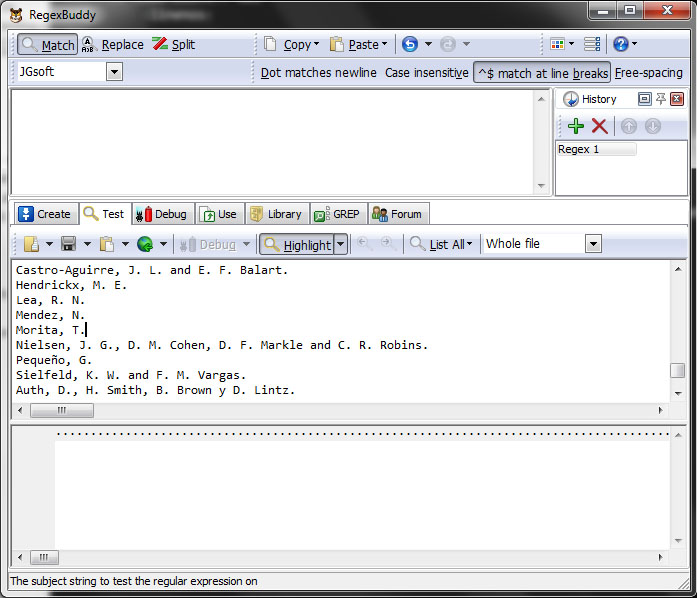
Copy and paste from text area 3, to text area 2 and delete the regex pattern from text area 1
Now all is ready to construct pattern to parse each author, in this case only have two groups, group 1 is author and group 2 is the field separator and regex pattern is: (.+?,\s[A-Z.\s]+?|.+?)(\sand\s|\sy\s|,\s|\s\(.+?\)\.?|\.\s$|$)
(.+?,\s[A-Z.\s]+?|.+?) .- Match . any single caracter + betwen one and ulimited times ? as few times is posible, , coma \s, any character in class [A-Z.\s], + betwen one and ulimited times ?, as few times is posible or match . any single caracter + betwen one and ulimited times ? as few times is posible. The first option is to match with first author, that always appear like this: Balduzzi first name ,|_| coma and space A. P. and surname composed by capital letters, dots and space. Second option is to match with remaining authors.
(\sand\s|\sy\s|,\s|\s\(.+?\)\.?|\.\s$|$) .- Match \s space and the word “and” \s space, or \s space y the character “y” \s space, or , coma \s space , or \s space \( open parenthesis . any single caracter + betwen one and ulimited times ? as few times is posible \( close parenthesis \. dot can be appear ? zero or one time, or \. dot \s can be appear ? zero or one time, or \. dot \s space $ end of line, or $ end of line. In this case each option is one posible field separathor.
Test pattern in RegexBuddy
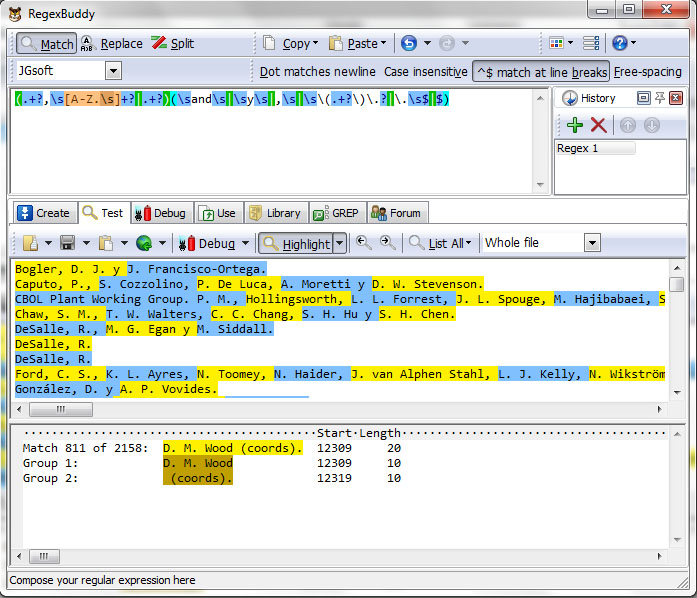
- When regex pattern is ready, continue completing the rule in XML file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
<authors> <value>${1}</value> <regex>(.+?,\s[A-Z.\s]+?|.+?)(\sand\s|\sy\s|,\s|\s\(.+?\)\.?|\.\s$|$)</regex> <struct> <aouthor tag="true"> <attr> <role>nd</role> </attr> <value>${1}</value> <postvalue>${2}</postvalue> </oauthor> </struct> <postvalue>${2}</postvalue> </authors>
- Add new regex into authors tagname
- Added struct to regex
- And the content of struct is oauthor with default attribute role and default value nd
Second example is parse surname and fname in oauthor
Create new new regex pattern to parse surname and fname in oauthor
Again choose List All → List all matches of group 1 on Test tab.
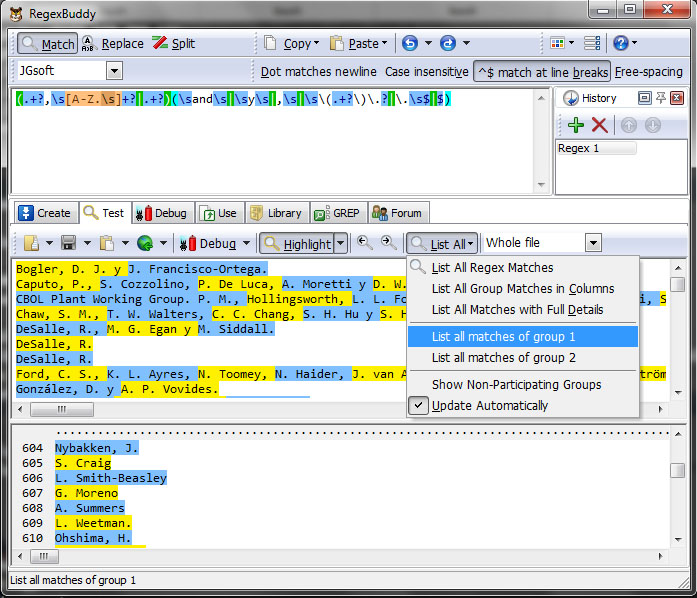
Copy and paste from text area 3, to text area 2 and delete the regex pattern from text area 1
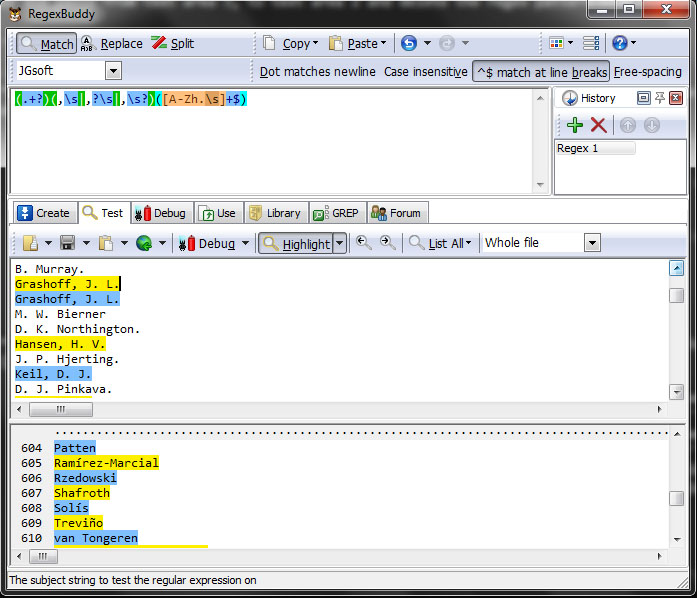
- In this can we have two options.
The first option is when autor appear like this: Caputo surname ,|_| coma and space P. and fname and can parsed with regex pattern (.+?)(,\s|,?\s|,\s?)([A-Zh.\s]+$)
(.+?) .- Match . any single caracter + betwen one and ulimited times ?, as few times is posible.
(,\s|,?\s|,\s?) .- Match ,\s coma and space, or , coma ? apear zero or one time \s space or , coma \s space ? apear zero or one time.
([A-Zh.\s]+$) Match any character in class [A-Zh.\s], + betwen one and ulimited times ? at $ end of line.
Test pattern in RegexBuddy
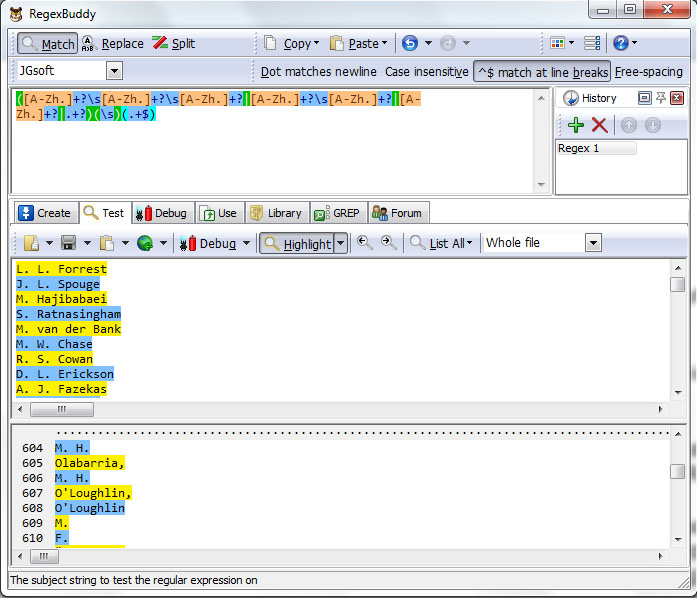
Second option is when autor appear like this: D. L. fname |_| space Erickson and surname and can parsed with regex pattern ([A-Zh.]+?\s[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?|.+?)(\s)(.+$)
([A-Zh.]+?\s[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?|.+?) .- Match any character in class [A-Zh.\s], + betwen one and ulimited times ? as few times is posible \s space, any character in class [A-Zh.\s], + betwen one and ulimited times ? as few times is posible \s space, any character in class [A-Zh.\s], + betwen one and ulimited times ? as few times is posible, or any character in class [A-Zh.\s], + betwen one and ulimited times ? as few times is posible \s space, any character in class [A-Zh.\s], + betwen one and ulimited times ? as few times is posible, or any character in class [A-Zh.\s], + betwen one and ulimited times ? as few times is posible, or . any single caracter + betwen one and ulimited times ?, as few times is posible.
(\s) .- Match \s space.
(.+$) .- Match . any single caracter + betwen one and ulimited times ?, as few times is posible.
Test pattern in RegexBuddy
- When regex pattern is ready, continue completing the rule in XML file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
... <aouthor tag="true"> <attr> <role>nd</role> </attr> <value>${1}</value> <multiple> <option> <regex>(.+?)(,\s|,?\s|,\s?)([A-Zh.\s]+$)</regex> <struct> <surname tag="true"> <value>${1}</value> <postvalue>${2}</postvalue> </surname> <fname tag="true"> <value>${3}</value> </fname> </struct> </option> <option> <regex>([A-Zh.]+?\s[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?|.+?)(\s)(.+$)</regex> <struct> <fname tag="true"> <value>${1}</value> <postvalue>${2}</postvalue> </fname> <surname tag="true"> <value>${3}</value> </surname> </struct> </option> </multiple> <postvalue>${2}</postvalue> </oauthor> ...Added multiple with two options
- First option contains regex pattern (.+?)(,\s|,?\s|,\s?)([A-Zh.\s]+$) with struct fname and surname
- Second option contains regex pattern ([A-Zh.]+?\s[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?\s[A-Zh.]+?|[A-Zh.]+?|.+?)(\s)(.+$) with struct surname and fname